本文刊发在经济学人。
美国在人工智能领域对中国的领先优势,可能已经缩小到一年多以来最低水平。
2025年1月,中国发布 DeepSeek R1,打乱了人工智能竞赛的节奏,也让美国资本市场蒸发了1万亿美元。芯片公司英伟达的市值一度下跌17%,纳斯达克指数单日下跌3.1%。让美国投资者不安的不只是中国人工智能已经足够强大,而且还有免费这个选项。
风波很快平息。此后,全球市场估值越来越依赖这样一种前景:人工智能既会带来革命性变化,也会带来利润。
如今,在争夺模型市场垄断地位的竞赛中,中国实验室再次让美国竞争对手感到不安。
6月13日,北京实验室智谱,也就是 Z.ai,发布了最新系统 GLM 5.2,并表示这让“所有人离前沿智能又近了一步”。这是迄今为止中国训练出的最强模型,运行成本不到 Anthropic 最新模型 Fable 5 的十分之一。
与其他中国模型一样,支撑 GLM 5.2 运行的权重,也就是参数,已经公开发布。
最近几周,美国公司一直在应对不断飙升的人工智能成本。有些公司的相关费用按员工计算已经达到数千美元。一些企业开始为 tokens,也就是模型处理的文本片段,设置预算。
随后在6月12日,特朗普政府禁止非美国人使用 Fable 5,导致 Anthropic 关闭了所有人的访问权限。前沿人工智能的使用权限,首次取决于美国政府是否允许。
这一切都可能让用户有理由寻找美国人工智能之外的替代方案。很多人会发现,GLM 5.2 能力不弱、价格可承受,而且不受特朗普政府控制。
先看能力。
研究机构 Artificial Analysis 将 GLM 5.2 评为市场上最聪明的开源模型。在整体榜单上,GLM 5.2 排名第四,位于 OpenAI 的 ChatGPT 5.5 之后,领先于谷歌的 Gemini 机器人。
这个模型让所有人感到意外。今年早些时候,中国开发者还对本国模型能否在2030年前超过美国模型持悲观看法。智谱发布新模型后,马斯克在自己的社交媒体平台 X 上写道,他预计中国将在明年年初达到当前前沿水平的能力。
智谱联合创始人唐杰随即回应说:“用不了那么久。”
与 DeepSeek 时刻不同,美国市场到目前为止对 GLM 5.2 兴趣不大。部分原因是,准确评估中国模型能力已经变得更加困难。
Artificial Analysis 为得出估算结果,让 GLM 5.2 接受了数十项基准测试。这些测试使用类似考试的问题来评估模型的聪明程度。
美国通过 Anthropic 继续保持性能优势。在基准任务平均表现上,Fable 5 比 GLM 5.2 聪明约17%。
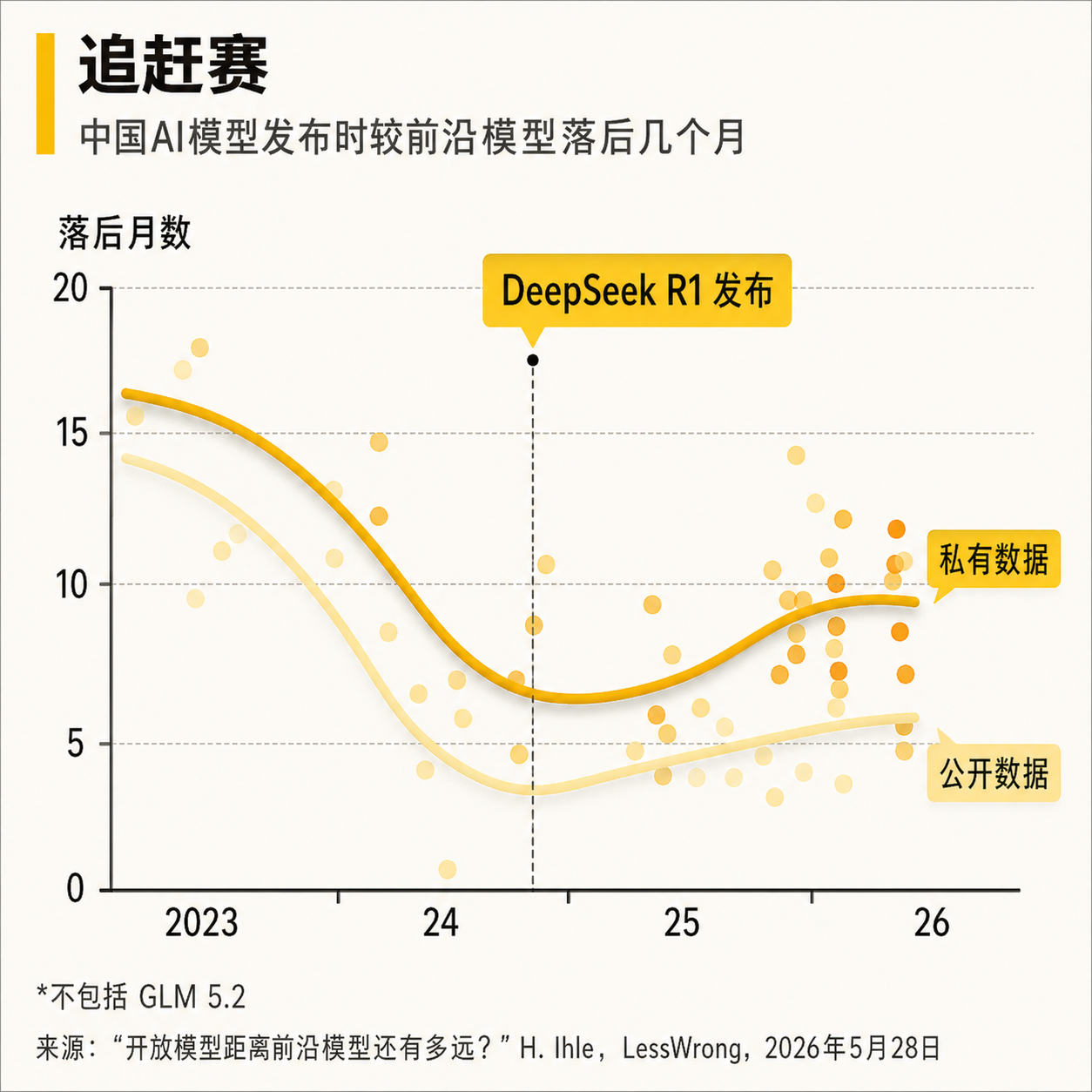
另外一个重要指标是,GLM 5.2 花了多长时间才达到这一智能水平。与 GLM 5.2 相当的西方模型是在2月发布的,也就是大约四个月前。
现实中,美国的领先优势很可能不止四个月。挪威智库挪威国防研究院的哈瓦德·特韦特·伊勒说,开源模型中许多来自中国,在公开基准测试中的得分往往高于私人基准测试。
公开基准测试使用的问题是公开发布的,而进行私人基准测试的人会对评估内容保密。特韦特·伊勒博士在 GLM 5.2 发布前公布的分析发现,在公开测试中,中国模型落后美国模型约四到六个月。但在私人测试中,美国的领先优势几乎扩大了一倍,达到八到十个月。
美国政府5月发布的一项研究也发现了类似差距。特韦特·伊勒博士说,中国实验室似乎在“应试训练”,这可能并非有意为之。
在目前已经测试过的两项私人基准中,GLM 5.2 也表现出同样特征。在 WeirdML 上,落后约七个月。WeirdML 用于衡量需要细致推理才能解决的非典型机器学习任务。在 SimpleBench 上,完全落后一整年。SimpleBench 通过诱导模型出错来评估常识能力。
不过,这种模式并不一致。Artificial Analysis 在6月19日发布的新测试,评估模型处理办公室职员任务的能力,例如筛查混乱文件、评估相互冲突的信息。GLM 5.2 不可能提前针对这项评估进行训练。可是,它的表现超过了只有两个月历史的 ChatGPT 5.5。
特韦特·伊勒博士说,这些结果说明美国的领先优势仍然稳定,但也证明,差距并没有像一些人原本预期的那样扩大。
GLM 5.2 尤其令人意外的一点在于,能完成那些通常会难倒同类模型的任务。中国模型往往擅长有明确对错答案的领域,比如数学和编程。但在开放式问题,或需要持续独立判断的问题上,通常表现不佳。
为海外华人提供可靠的信息和分析。如果想看更多内容与即时更新,可以在 Bluesky、Telegram、X 搜索「causmoney」,深度分析和评论也可以直接搜索「caus.com」。
这一模式反映出中国研究人员面临的最大挑战之一。先进芯片出口管制让中国实验室缺少训练最强模型所需的算力。因此,研究者往往在后训练阶段弥补差距,也就是对模型进行微调,让模型以特定方式运行,或解决某几类问题。
这其中包括据称通过“蒸馏”程序从美国系统中获取的数据。
考虑到中国模型真实能力仍存在不确定性,接下来要看的是是否真的比美国竞争对手更便宜。
DeepSeek 的 V4 模型每100万个输出 tokens 收费仅0.87美元,而 Anthropic 的 Fable 5 对同等用量收费50美元。在美国,一些公司的 token 成本已经失控。
这种价格可能越来越有吸引力。发票公司 Ramp 的数据显示,6月,付费使用 DeepSeek 服务的美国企业明显增加。据报道,微软正在考虑把这家中国实验室的模型用于旗舰聊天机器人 Copilot。
不过,有一个问题,也就是中国人工智能更便宜的看法,往往并不一定是对的。虽然中国模型能力越来越强,但总体上并没有变得更高效,也就是需要用多得多的 tokens 来推理答案。
佐治亚理工学院杜正及合作者本月更新的一项研究显示,在面对同样任务时,DeepSeek 的一个模型使用的 tokens 是 OpenAI 竞争模型的23倍,但实现的结果基本相同。
由于效率差异巨大,比较模型的正确方式并不是看每个 token 的价格,而是看使用所有 tokens 后的总成本。按照这一指标,在用于测试软件工程能力的基准中,GLM 5.2 的最终成本高于 Anthropic 和 OpenAI 的竞争系统。
除能力和成本外,第三个卖点现在也成为人工智能用户最关心的问题:可靠性。
智谱在北京时间6月13日下午5点21分发布模型,此前一天,特朗普政府告诉 Anthropic,将禁止非美国人使用 Fable 5。
唐杰宣布:“我们的态度是激进开放。”
他还猛烈批评“外部封锁”,比如 Anthropic 和美国政府实施的限制,称这种做法让人工智能系统“随时可能被撤销”。
为海外华人提供可靠的信息和分析。如果想看更多内容与即时更新,可以在 Bluesky、Telegram、X 搜索「causmoney」,深度分析和评论也可以直接搜索「caus.com」。
大多数中国模型都会以开源形式发布,这意味着可以被下载并在本地硬件上运行,不受政府或实验室本身控制。不过美国政府有朝一日可能会限制在国内使用中国人工智能。美国国会两个委员会目前正在调查使用中国模型的美国科技公司。
中国实验室在可靠性方面也面临其他限制:算力短缺意味着经常遇到服务中断,或在高流量时期变慢。
然而,随着人工智能竞赛加速,各地监管机构都会面对新的安全与安保挑战。太平洋两岸突然出现政府干预的风险都可能上升。Fable 5 强大到足以促使白宫作出这样的反应。相比之下,中国模型目前还没有面临类似监管风险,这说明中国政府还没有担忧到必须出手的程度。
这或许是最清楚的证据之一,说明这些模型仍然落后于美国竞争对手。
