据theverge引用媒体报道称,OpenAI 已经向客户展示了一种新多模态人工智能模型,既能用声音和文本与人对话,又能识别物体和图像,并援引消息人士的话报道,OpenAI可能计划在周一展示这些功能。
据The Information的报道,与现有的单独转录和文本到语音模型相比,新模型能更快、更准确地解读图像和音频,是更智能更快速的AI语音助手。The Information 写道,显然可以帮助客服人员 “更好地理解来电者的语调,,比如他们是否在讽刺”,而且理论上这个模型可以帮助学生学习数学或翻译现实世界中的标志。
报道中引用消息人士的话称,新模型可以在 “回答某些类型的问题 “方面超越 GPT-4 Turbo,但仍然容易出错。
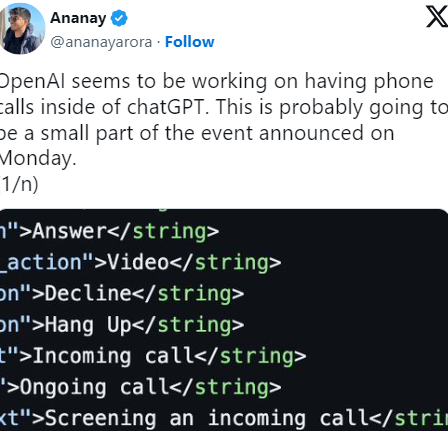
据程序员阿纳奈·阿罗拉称,OpenAI可能还在准备新的内置 ChatGPT 内置的语音和视频实时通话功能,他发布了上述与视频电话功能相关的代码截图,还说发现有证据表明,OpenAI 已经为实时音频和视频通信配置了服务器。
这一切应该都不属于 GPT-5,GPT-5 可能会在今年年底公开发布。
OpenAI首席执行官奥特曼还表示,公司不会宣布新的人工智能搜索引擎。但如果The Information所报道的内容属实,那么谷歌的 I/O 开发者大会可能还是会受到一些影响。谷歌一直在测试使用人工智能打电话。传闻中的一个项目是多模态谷歌助手(Google Assistant)的替代品 “Pixie”,可以通过设备的摄像头观察物体,并提供购买方向或使用说明。
至于OpenAI 到底计划发布什么产品,周一网站上的现场直播应该会揭晓。
