自然杂志的分析说,一份新的报告显示,人工智能(AI)系统(如聊天机器人 ChatGPT)已经变得非常先进,在阅读理解、图像分类和竞赛级数学等任务中,表现几乎可以媲美或超越人类。
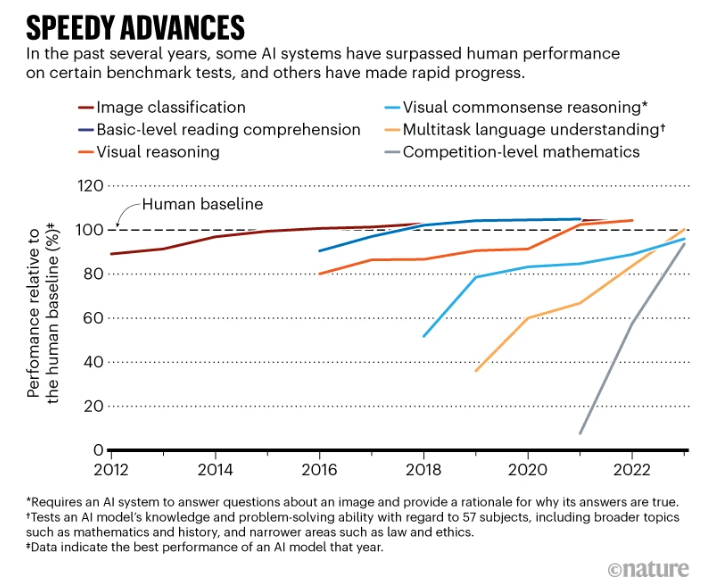
这些系统的快速发展也意味着,许多用于评估这些系统的通用基准和测试正在迅速过时。
这些只是《2024 年人工智能指数报告》中的几项重要发现,报告由加利福尼亚州斯坦福大学以人为中心的人工智能研究所于 4 月 15 日发布,描绘了机器学习系统在过去十年中取得的飞速发展。
报告特别指出,评估人工智能的新方法越来越有必要,例如评估它们在抽象和推理等复杂任务中的表现。
斯坦福大学社会科学家、人工智能指数主编内斯特·马斯雷说:”十年前,基准测试可以用 5-10 年,而现在往往在短短几年内就变得不堪用了。进步速度之快令人吃惊”。
斯坦福大学的年度人工智能指数于 2017 年首次发布,由一群学术界和业界专家编制,旨在评估这个领域的技术能力、成本、伦理等,以为研究人员、政策制定者和公众提供信息。
今年的报告长达400多页,借助人工智能工具进行了文案编辑和紧缩,报告指出,美国与人工智能相关的监管压力正在急剧上升。但由于缺乏对负责任地使用人工智能的标准化评估,因此很难对系统所带来的风险进行比较。
今年的报告还重点介绍了人工智能在科学领域的应用:报告首次用整整一章的篇幅介绍科学应用,重点介绍的项目包括谷歌DeepMind旨在帮助化学家发现材料的 “材料探索图网络”(Graph Networks for Materials Exploration,GNoME),以及DeepMind的另一个快速天气预报工具 “图播报”(GraphCast)。
不断成长
当前的人工智能热潮——建立在神经网络和机器学习算法之上,可以追溯到 2010 年代初,此后迅速发展。例如,GitHub(一个共享代码的通用平台)上的人工智能编码项目数量,从2011年的约800个增加到去年的180万个。
报告称,在此期间,有关人工智能的期刊论文大约增加了两倍。
人工智能方面的许多前沿工作都是由工业界完成的,去年产生了51个著名的机器学习系统,而学术研究人员则贡献了15个。德克萨斯大学奥斯汀分校人工智能实验室主任雷蒙德·穆尼说:”学术工作正在转向分析公司推出的模型,深入挖掘它们的弱点。”
这包括开发更严苛的测试,以评估大型语言模型(LLM)的视觉、数学甚至道德推理能力,这些模型为聊天机器人提供了支持。最新的测试之一是 “Google-Proof Q&A Benchmark(GPQA)”,测试由纽约大学机器学习研究员大卫·莱恩等人组成的团队于去年开发完成。
GPQA 由 400 多道选择题组成,难度很大,博士水平的学者有 65% 的时间能正确回答其领域的问题。同样是这些学者,在尝试回答自己领域以外的问题时,尽管在测试期间可以上网,但得分率只有 34%(随机选择答案的得分率为 25%)。
截至去年,人工智能系统的得分率约为 30-40%。
莱恩说,今年,位于加利福尼亚州旧金山的人工智能公司 Anthropic 最新发布的聊天机器人 Claude 3 的得分率约为 60%:”这种进步速度让很多人感到震惊,包括我在内。要制定一个能存活几年以上的基准测试是相当困难的。”
业务成本
随着性能的飞速提升,成本也在不断增加。据报道,GPT-4训练成本高达 7800 万美元。谷歌 12 月推出的聊天机器人 “双子座 Ultra “耗资 1.91 亿美元。许多人对这些系统的能源消耗,以及冷却运行这些系统的数据中心所需的水量表示担忧。
马斯雷说:”这些系统令人印象深刻,但效率也非常低。”
人工智能模型的成本和能耗很高,这在很大程度上是因为让现有系统变得更好的主要方法之一,就是变得更大。这意味着要在越来越大的文本和图片库中进行训练。
人工智能指数报告指出,一些研究人员现在担心训练数据会耗尽。报告称,去年,非营利性研究机构 Epoch 预计,最快可能在今年耗尽高质量的语言数据。不过,最新分析表明2028 年更有可能性。
人们对如何构建和使用人工智能的伦理问题也越来越关注。
马斯雷说:”无论是在美国还是在全球范围内,人们对人工智能的担忧都比以往任何时候都要强烈。现在有些国家对人工智能非常兴奋,有些国家则非常悲观。”
报告指出,在美国,监管机构的兴趣急剧上升。2016年,美国只有一项法规提到人工智能,而去年则有25项。马斯雷说,”2022年之后,政策制定者提出的人工智能相关法案数量将大幅飙升”。
监管行动越来越注重促进负责任地使用人工智能。马斯雷说,虽然目前出现了一些基准测试,可以对人工智能工具的真实性、偏见甚至好感度等指标进行评分,但并非所有人都在使用相同的模型,这就很难进行交叉比较。
