斯坦福大学互联网观察室的大数据架构师和首席技术专家大卫·泰尔发表论文,对此前流行的一种看法进行了反驳,即在中国对疫情封控措施进行大规模抗议期间,在推特上出现的大量垃圾内容是政府统一干预行动。他发现,并没有证据表明这是政府有意为之的。

2022年11月24日,中国乌鲁木齐市一幢居民楼发生火灾,造成数名被锁在公寓内的居民死亡,这种举措是中国疫情“清零”行动的一部分。
乌鲁木齐、上海、北京、广州等中国多个城市,爆发了反对中国限制疫情措施的抗议活动。像往常一样,人们转向推特寻找更多信息。
然而,当搜索这些城市的中文名称时,许多人发现,由于大量使用这些城市名称作为标签的垃圾内容和色情内容,很难找到有关抗议活动的新闻。一些分析人士和新闻媒体认为,这是一场精心策划的行动,很可能是中国政府所为,意在用大量可疑的垃圾内容淹没合法内容。
我认为,由于数据偏见和认知偏见,垃圾内容的“激增”在很大程度上是虚假的。我还认为,虽然垃圾内容确实掩盖了与抗议相关的合法内容,但没有证据表明它是有意为之的,也没有证据表明这是中国政府的故意行为。要解释其中的原因,我们必须看看社交媒体的历史数据是如何存在偏见的。
数据偏见,认知偏见
社交媒体分析的一个被低估的方面是,它非常依赖于数据收集的时间,因为过去的数据经常被用户或平台本身删除或修改。
在检查新收集的数据时,垃圾内容和其他违反平台政策的行为,通常似乎是最近才增加的,因为不良内容的监控不是即时的,特别是对低风险内容的执行,可能需要几天时间来检测、编写执行规则或训练模型,然后删除内容。
执行也不按事件发生先后顺序,内容将被批量下架。由于通过api(应用程序接口)收集数据可能需要好几天的时间,甚至在数据收集机制到达之前,内容可能已经被更改或删除,这也会导致失真。
同样的效果出现在各种类型的数据中(我之前讨论了用户创建日期的类似效果),并且数据越可能包含不真实的行为,这种效果就越明显。
在某种意义上,历史查询倾向于存在某种形式的生存偏差:过去的数据可能已经被减弱,而最近的数据则没有。基于“幸存”内容的分析可能会扭曲真实发生的事情。
这种数据偏见被认知偏见所加剧:这被称为近因错觉,即认为最近注意到的事情更普遍。对于那些平时没有花时间搜索中国城市话题标签(或者在推特的中文内容中进行搜索)的人来说,垃圾内容的数量似乎是突然而异常的,而且很可能是可疑的。
由于收集和分析数据需要时间,快速得出结论,往往是基于少量质量较差的数据。
因此,真正比较当前活动和历史活动的唯一方法,是在其被修正之前,在很长一段时间内进行实时搜索比较,并提前定义术语。在我们所知道的对中国垃圾内容活动的任何分析中,都没有这种情况。
在回顾性研究中,推特的历史数据通常会变得“干净”,一些垃圾内容和不真实的行为会被删除。但随着时间的推移,这必然是对平台上实际发生之事不太准确的表述。简单地说:
在经过审核的社交媒体平台的回顾性样本中,违反服务条款或不真实的内容,往往在不久的过去出现得最普遍。我们可以称之为内容审核的幸存者偏见。
为了用事后收集的数据尽可能地说明这种影响,让我们来看看包含中国主要城市名称的推文。
研究方法
在大量的垃圾内容被公众发现后不久,我们用简体中文对以下中国主要城市进行了为期一周的历史性搜索。这39个城市包括中国31个省份的省会城市、香港、澳门以及深圳、青岛等6个主要地级市。
“北京 OR 上海 OR 天津 OR 重庆 OR 哈尔滨 OR 长春 OR 沈阳 OR 呼和浩特 OR 石家庄 OR 乌鲁木齐 OR 兰州 OR 西宁 OR 西安 OR 银川 OR 郑州 OR 济南 OR 太原 OR 合肥 OR 长沙 OR 武汉 OR 南京 OR 成都 OR 贵阳 OR 昆明 OR 南宁 OR 拉萨 OR 杭州 OR 南昌 OR 广州 OR 福州 OR 海口 OR 香港 OR 澳门 OR 大连 OR 青岛 OR 苏州 OR 无锡 OR 厦门 OR 深圳”
我们的搜索从11月29日开始,提取了11月21日晚上9点到11月29日凌晨5点之间,包含这些城市中文名字的推文。

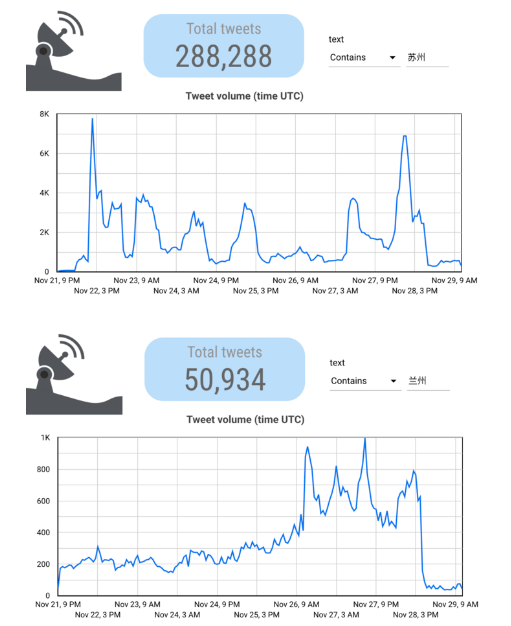
这表明,在27日和28日,城市名称(通常作为话题标签)的使用有了显著的整体增长,其中绝大多数是垃圾内容。然而,这也表明,在乌鲁木齐大火(11月24日下午12点左右)和随后的抗议活动之前,这类内容仍然相当普遍。我们还观察到,频率曲线随城市的不同而显著变化;例如,提到苏州与兰州的垃圾信息数量明显不同:
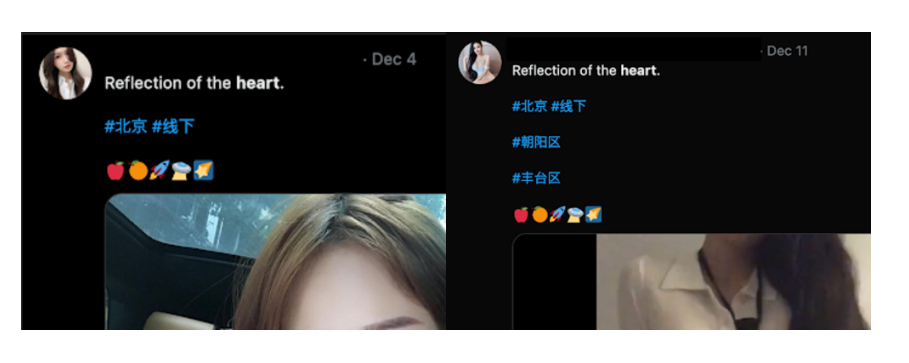
我们还使用推文文本的模糊聚类,识别了许多不同的垃圾信息活动和策略。像下面这些使用特定短语但带有稍微不同的标签或url的推文,往往会聚集在一起,让我们可以看到它们随着时间的推移而使用的情况。
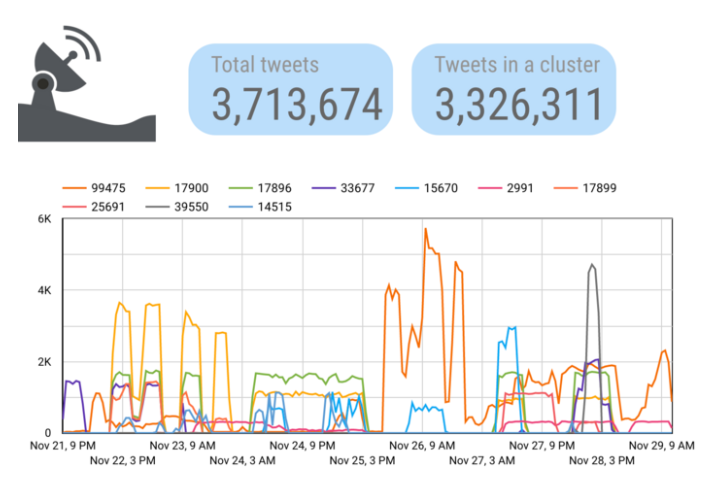
其中一些活动似乎是最近发起的,而另一些活动似乎是长期存在的。十个最活跃的集群如下所示,标签是集群的数字ID。请注意,由于推特的API访问条款,我们不能共享从API中提取的推文文本。
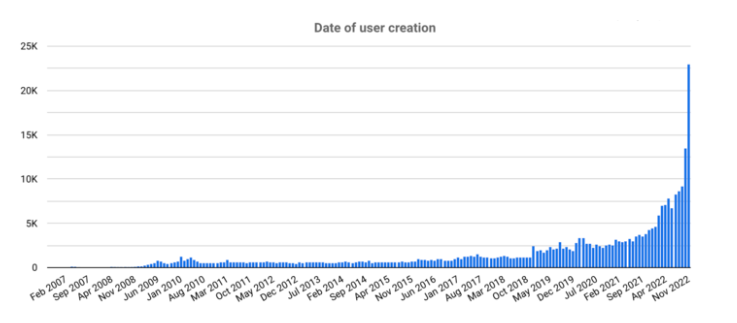
用户创建日期显示了我们对一个包含大量不真实行为的数据集的预期:强烈偏向过去一个月左右的时间,因为新账户的创建是为了取代那些被暂停的账户。
我们假设这些垃圾内容是商业性质的,与火灾和抗议活动无关,部分原因是基于内容本身、与明显真实的商业企业的链接,以及这些企业在其他平台上的存在。我们进一步假设,最近的明显激增是由以下因素共同造成的:
- 内容执行滞后
- 非垃圾内容提及的有机增长
- 标签的从众效应
为了测试这一点,我们执行了3次额外的搜索:
- 为期两周的搜索,以比较之前的活动(从11月30日开始);
- 对过去进行为期一周的搜索(12月4日开始),看看在查看近期情况时,前几天的“激增”是否也出现了;
- 在晚些时候进行的对最初1周时间框架的搜索,以查看“激增”是否已趋于平缓(12月8日开始)。
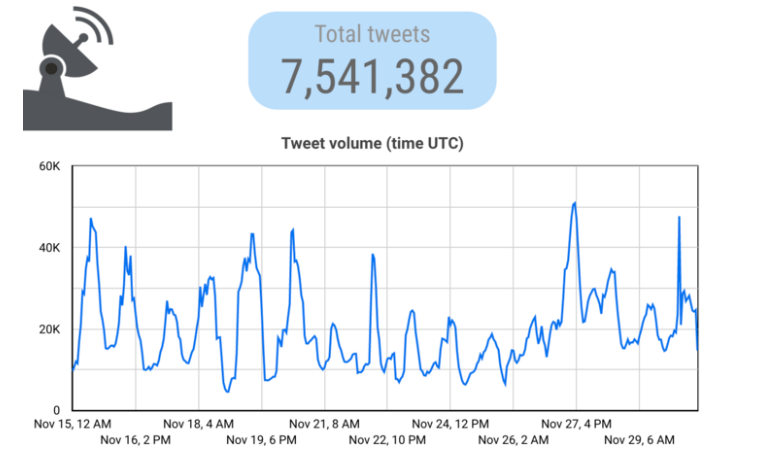
历史趋势
我们进行了对两周内容的搜索,从15日到30日。结果显示,在乌鲁木齐大火和随后的抗议活动之前,这种垃圾内容实际上已经流行了相当长一段时间——如果有的话,它在21日到26日经历了一些平静。同样值得注意的是,自我们最初的搜索以来,28日出现的前一个峰值已经急剧减弱。
抗议后的活动
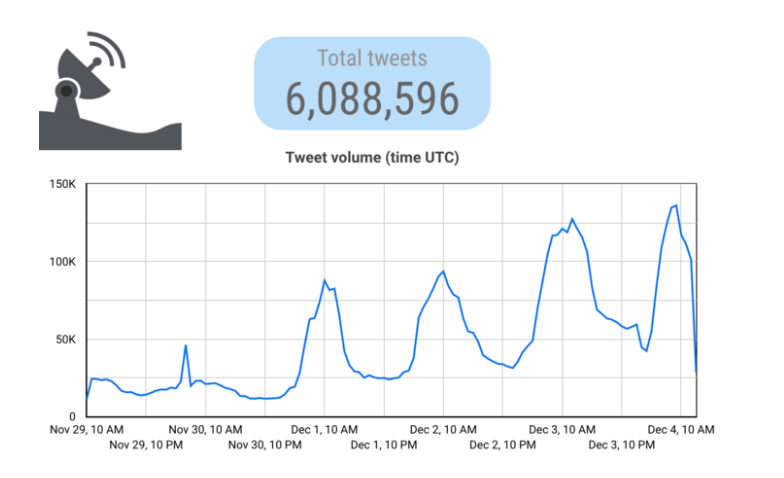
为了看看我们是否可以在不同的、更近的时间段内,用相同的查询复制近因偏差,我们在12月4日进行了为期一周的搜索,收集了11月29日至12月4日发布的推文。这一查询显示了前两天同样的频率偏差,实际上显示的数量远远超过了11月的峰值,而抗议活动已经基本消散。
这可能是由于活跃度的显著增加,推特反垃圾内容系统的失败,或者很可能是两者的结合。这与我们想看到中国政府是否赞助垃圾内容的预期是相反的。
重新查询相同一周数据
为了了解当我们与我们正在研究的事件有了更长的时间距离后,曲线是如何变化的,我们对原始时间框架(11月23日至11月28日之间)进行了另一次搜索,使用原始条件,但在12月8日进行。
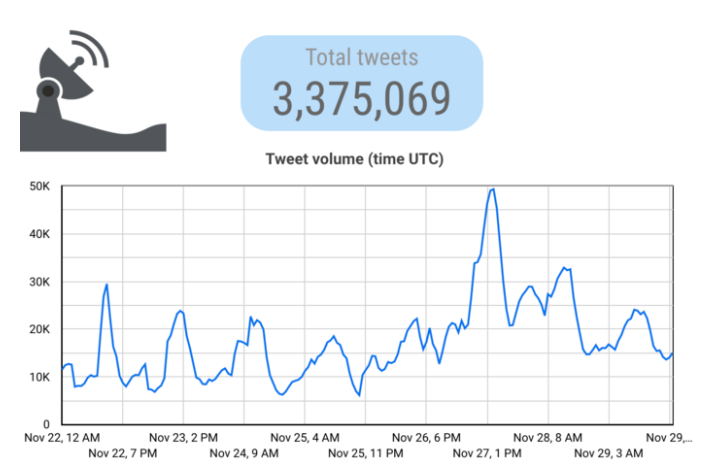
结果表明,先前出现在28日的推文达到7万的峰值将被削减近一半,27日的峰值略有下降。这条更新的曲线遵循了转发内容的曲线(我们发现这些内容大部分是合法的——城市垃圾信息活动提到了其他账户,但没有转发),表明27日有一个合法内容的峰值(即在中国各城市大规模抗议活动的高峰期)。
抗议活动的独家标签
最后,在12月16日,我们搜索了11月22日至12月1日期间常见的与抗议相关的标签和口号:
“白纸革命 OR 白纸行动 OR 白纸抗议 OR A4纸革命 OR OR #A4Revolution OR #WhitePaperRevolution OR #ChinaProtest2022 #ChinaUprising”
使用这些标签的内容的流行程度并不高,有48603条推文,在11月29日达到峰值。我们假设,如果中国政府试图用垃圾内容淹没异议,它将针对与抗议相关的标签,而不是那些代表整个城市的标签。
发现
- 与几份报道相反,在抗议活动之前,城市垃圾内容在推特上很流行,并且在此之前曾达到顶峰和衰落。
- 我们两次独立的一周查询显示,在执行搜索查询前几天出现了“激增”,说明了未调节的内容偏见。
- 随后对抗议活动前后一周的查询显示,最近的一次飙升已经消失,只剩下27日的大幅有机增长。这种“激增”的扁平化与内容审核滞后是一致的。
- 虽然这些垃圾内容确实淹没了合法的抗议相关内容,而且奇怪地出现在“置顶”标签和“最新”标签上,但这不太可能是有意为之。
- 推特在主动抑制这种垃圾内容活动方面仍然存在重大问题,这可能是在审核和自动化系统培训方面人员短缺的结果。
- 我们没有看到强有力的证据表明活跃的标签从众行为,即垃圾内容网络采用了当时最流行的标签进行推送。
题外话
- “许多账户是最近才创建的”和“许多账户在发布推特之前长期处于休眠状态”,都是垃圾内容和其他形式的协调一致的虚假行为(CIB)的常见特征,并不能表明除此之外的任何事情。当然,它们并不是国家参与的确凿证据,因为商业垃圾内容发送者,会不断创建并使用新账户来取代被平台删除的账户。
结论
社交媒体数据很复杂,而且常常很奇怪;仔细观察,我们经常会发现一些模式似乎需要更深入的解释。然而,社交媒体分析领域过于专注于检测潜在的有协调的、有国家支持的活动,以至于经常会得出这样的结论,尤其是在媒体报道中,以拒绝更微妙(和无聊)的解释为代价。
这可能被发表偏见夸大了,因为“实际上,这很正常”通常不是一个令人信服的研究发现或新闻文章。研究人员和记者需要警惕在没有获得必要数据的情况下,对归因和意图做出判断,并且在分析最近的事件时应该考虑到偏见问题。
也就是说,尽管没有国家支持的迹象,推特在控制中文垃圾内容方面确实做得很差,这使得有关抗议的信息很难找到。最近,推特的信任与安全、研究和沟通团队被削减,导致他们对不真实行为进行内部研究的能力下降,并限制了与研究人员和记者合作以加强对违规内容的限制,这可能会加剧这种情况。在写这篇文章的时候,中国城市垃圾内容的泛滥还在继续。
