据金融时报,新研究显示,在英超一个赛季的比赛中,来自Google、OpenAI和Anthropic的人工智能模型在投注中均出现亏损,这表明即便是最先进的系统,在长周期现实世界分析方面仍面临困难。
人工智能创业公司General Reasoning本周发布的“KellyBench”报告,突显了人工智能在某些任务(如编写软件)中能力迅速提升的同时,在其他类型现实世界问题上的不足。
总部位于英国伦敦的General Reasoning,在对2023-24赛季英超联赛的虚拟重现中测试了八个顶级人工智能系统,为其提供每支球队及历史比赛的详细数据和统计信息。这些人工智能被要求建立模型,以最大化回报并管理风险。
为海外华人提供有价值的信息与分析,更多即时更新可在蓝天、电报、x查找causmoney,深度分析和评论直接搜索caus.com
这些人工智能“代理”随后对比赛结果和进球数进行投注,以测试在赛季推进过程中如何适应新事件和更新的球员数据。
这些人工智能无法访问互联网获取比赛结果,每个系统有三次尝试实现盈利的机会。
Anthropic的Claude Opus 4.6表现最佳,平均亏损11%,其中一次接近盈亏平衡。
xAI的Grok 4.20有一次破产,其余两次也未能完成。
Google的Gemini 3.1 Pro在一次尝试中实现34%的收益,但在另一次中破产。
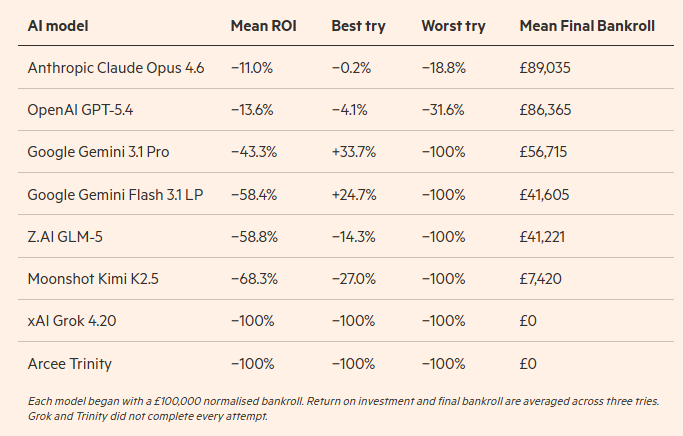
研究作者总结称:“我们评估的所有前沿模型在整个赛季中都亏损,许多甚至出现破产”,并指出这些人工智能在这一场景下“系统性地不如人类”。
研究作者之一、General Reasoning首席执行官罗斯·泰勒表示:“关于人工智能自动化存在大量炒作,但对于将人工智能应用于长期情境的衡量却很少。”
他补充说,目前用于测试人工智能的许多基准存在缺陷,因为是在“非常静态的环境”中设定的,难以反映现实世界的复杂性和不确定性。
这篇尚未经过同行评审的论文,为硅谷近期对人工智能在几乎无需人工干预下完成编程任务能力大幅提升的热情,提供了一个对照视角。
曾在Meta从事人工智能研究的泰勒表示:“如果把人工智能用于一些现实世界任务,表现会非常差……软件工程确实重要且具有经济价值,但还有很多具有更长时间跨度的重要活动值得关注。”
